
Note: You can find the English version after the Chinese one.
(文末有对应演技视频)
【中文版 Chinese version】
00 引言
1. 三个层次聊测试体系
测试人员缺乏体系化思维?
新建产品团队或者新启项目,如何搭建质量保障体系?
大家都接触过不计其数的测试、质量方面的文章或者培训课程,内容不乏测试实践、技术相关,但是却很难构建自己的测试体系。基于很多朋友类似的困惑,结合本人多年的团队实践和咨询经验,从基础、进阶和高级三个不同的层次来跟大家探讨测试体系化思维的构建。
2. 基础篇概述
之前写过一篇文章《神圣的QA》,是面向想从事QA工作的毕业生同学的,文中有讲到五个测试基本职责:

- 理解和澄清业务需求
- 制定策略并设计测试
- 实现和执行测试
- 缺陷管理与分析
- 质量反馈与风险识别
本文基础篇的内容将从这五个职责出发,分享测试的体系化思维需要关注的各个方面。
原文中基于“生产杯子”的需求对于五个测试基本职责有解释,本文将展开每个职责,从测试实践和方法集的角度来分析测试需要做什么和怎么做。
01 测试基本职责之一:理解和澄清业务需求
第一个测试基本职责是理解和澄清业务需求。
业务需求是软件开发的源头,正确理解需求的正确性不言而喻,理解和澄清需求也是测试工作至关重要的一部分。
1. 理解和澄清业务需求的维度
具体该如何去理解和澄清需求呢?我认为测试人员可以从以下三个维度去理解和澄清业务需求:
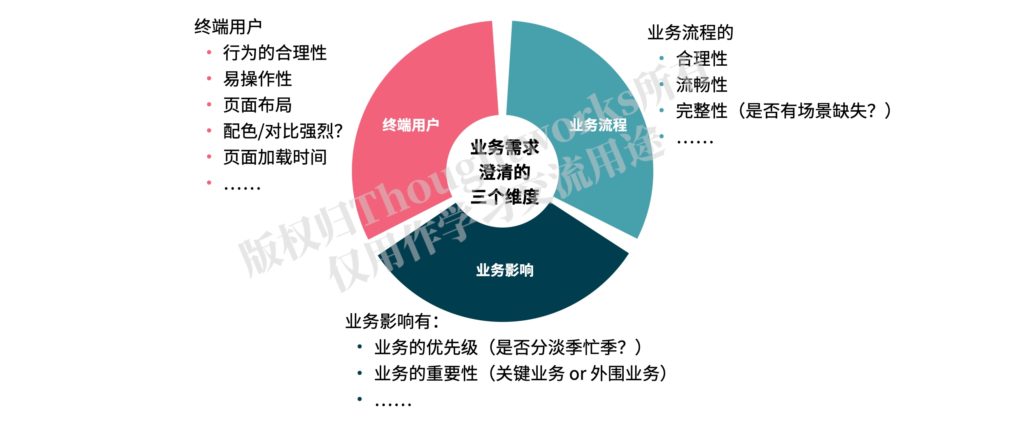
关于这几个维度的详细内容,在文章《敏捷测试如何优化业务价值》中有介绍。
2. 需求的可测试性
正确理解业务需求以外,对需求的描述质量也需要关注,其中需求的可测试性是最为重要的一个方面:
- 如果需求不可测,也就不可验收,没办法知道项目是否成功完成;
- 以可测试的方式编写需求,才能确保需求能够正确实现并验证。
需求的可测试性主要体现在下面三个维度:

完备性
需求的完备性主要指流程路径需要考虑全面,要求逻辑链路完整,既要有正向路径,也要包括异常场景。
比如:正确的用户名密码可以登录,不正确的用户名和密码登录会发生什么,这两者都是需要清晰定义的。
客观性
需求的描述不要用一些主观性的词语,而是需要客观的数据和示例来说明。比如下面这段主观性的描述是个非常糟糕的需求示例:
系统应该易于有经验的工程师使用,并且应该使得用户的出错尽可能少。
推荐采用《实例化需求》的方式来编写需求文档,将业务规则通过实例表述出来,不仅易于团队不同角色的理解,而且不容易产生歧义。
独立性
独立性主要是针对单个业务功能点(敏捷开发中的用户故事),要尽量的独立,跟其他功能边界清晰,减少因为依赖导致的功能点不可测。
比如:输入和输出要在同一个功能点里可验证,A功能点的输入不能通过B功能点的输出来验证。
敏捷开发中的用户故事有INVEST原则,将可测试性和独立性是分开描述的,我认为独立性也会影响可测试性,在这里把独立性作为可测试性的一个因素。
02 测试基本职责之二:制定策略并设计测试
制定策略并设计测试是第二个测试基本职责,是五个职责里最为关键的一个,涵盖的内容较多。看上去是策略和测试设计两部分,但实际上包含了测试所需要考虑的方方面面。下面挑选我认为比较有价值的内容分别介绍。
1. 一页纸测试策略
策略是方向,要做好软件的测试工作,离不开测试策略的指导。测试策略通常对于经验不是太丰富的测试人员来讲,可能挑战比较大。不过,我曾经提出来的“一页纸测试策略”可以很好地帮助测试人员去思考和制定自己项目适配的测试策略。一页纸测试策略如下如所示:
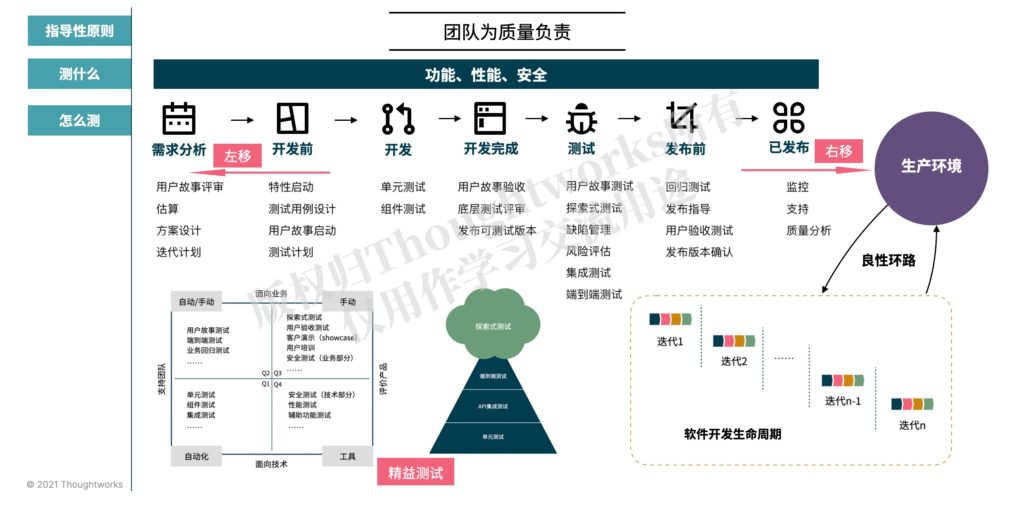
在一页纸测试策略里边,清晰地定义了测试策略需要考虑的三个部分:
- 指导性原则:团队为质量负责
- 测什么:测试的内容
- 怎么测:测试左移、测试右移和精益测试
更多详情请参考我的文章《一页纸测试策略》。
2. 测试流程与质量门禁
我们经常会发现有些团队的测试流程定义的也很清晰,但是每个环节要求做到什么效果并没有严格的要求,很多质量工作做的并不到位,导致后面测试阶段测试人员的压力巨大或者最终交付的质量并不高。
前面一页纸测试策略里已经有包含测试流程部分,这里再次单独提及主要是为了强调质量门禁的重要性。测试流程每个项目或团队可能都不太一样,但是不管测试流程包括哪些环节,每个环节的输出结果要求务必定义清晰,也就是要清晰定义每个环节的质量门禁,如下图所示:

注意:此图仅为示例,实际情况需要根据自身团队情况适配。
3. 典型测试类型
上面的流程图示例中列出了多种不同的测试类型,而实际的测试类型远不止这些。由于篇幅有限且这部分内容不是本文的重点,本文只介绍跟测试人员关系非常紧密的四种典型的测试类型。这四类测试的分类维度并不相同,这里不求详尽。不清楚但又感兴趣的同学,请自行网上搜索。
冒烟测试
冒烟测试来源于电路板的测试,也就是通电后看电路板是否冒烟,如果冒烟说明这块电路板是不可能正常工作的,也就不用去验证其他功能了。

对应到软件的冒烟测试,就是验证软件的最基本行为是否正常,例如:“程序是否运行?”,“用户界面是否打开?”或“单击事件是否有效?”等。只有冒烟测试通过,才有进一步开展验证软件功能测试的必要,否则就需要先修复重新出新版本才可以。
我们发现有的团队只对新开发功能进行冒烟测试,其实这是不太正确的,或者说这个测试就不叫冒烟测试。冒烟测试应该是对整个系统级别的基本行为进行验证,不区分什么新旧功能。
回归测试
回归测试的目的是验证新开发功能或者修复bug的时候,是否对已有功能有破坏。因此,回归测试的对象主要是针对已有功能,对于新功能的测试不叫回归。
回归测试的策略通常有四类:
- 全面回归:这种就是不分青红皂白,对所有已有功能进行全面的测试,这种策略成本较高,但是覆盖率较全,一般对质量要求特别高的金融类产品采用全面回归的方式较多。
- 选择性回归:这种一般是测试会跟开发进行沟通,了解当前代码编写可能影响到的范围,选择对这些受影响的功能模块进行回归。这种形式可能漏掉没有意识到但是关联到的功能,有一定的风险,但是较为经济的一种做法。
- 指标法回归:这种一般是团队对回归测试的覆盖率有要求,比如要覆盖50%的已有功能测试用例,执行回归测试不能低于这个覆盖率。这种光看指标数字的做法是最不推荐的,虽然覆盖率达标了,但是有可能该测的没有测到。
- 精准回归:精准回归就是当下非常热门的精准测试,这是采用技术的手段将代码改变所影响到的范围跟测试用例关联起来,精准地执行受影响的用例。这种质量最为有保证,但是精准测试实现成本是非常高的。
回归测试可以手动进行,也可以是自动化测试,但通常回归测试的量都会比较大,以自动化的方式进行会比较高效。
端到端测试
端到端测试基于测试覆盖的粒度分类,是针对单元测试和接口测试等而言的。
端到端测试是从头到尾验证整个软件及其与外部接口的集成,其目的是测试整个软件的依赖性、数据完整性以及与其他系统、接口和数据库等的通信,以模拟完整的业务流程。因此,端到端测试是最能体现用户真实业务行为的测试,有着非常重要的价值。
但是,由于端到端测试涉及到系统各个相关组件和外部依赖,其稳定性和执行成本相对都是比较高的。于是有了覆盖范围较小的接口测试和单元测试,这些测试一般都是通过隔离依赖来实现的测试,此处不再细述。
探索式测试
探索式测试由Cem Kanner博士于1983年提出,是针对脚本化测试而言的。
Cem Kanner对探索式测试的定义如下:
“探索式测试是一种软件测试风格,它强调独立测试人员的个人自由和职责,为了持续优化其工作的价值,将测试相关学习、测试设计、测试执行和测试结果分析作为相互支持的活动,在整个项目过程中并行地执行。”
探索式测试的核心旨在将测试学习、测试设计、测试执行和测试结果分析作为一个循环快速地迭代,以不断收集反馈、调整测试、优化价值。
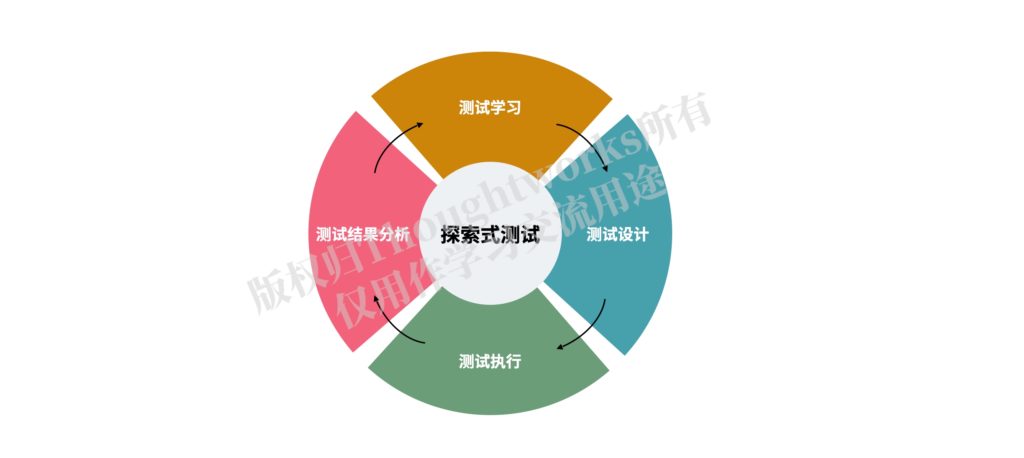
探索式测试特别需要测试人员的主观能动性,需要有较为宽松的鼓励测试创新的环境才能较好地开展,如果对于测试指标要求过高,测试人员主观能动性难以发挥的情况下,探索式测试的效果也很有限。
探索式测试是一种相对自由的测试风格,不建议被各种测试模型套住,也不建议严格规定探索式测试的执行方式,这些都会影响到探索式测试的发挥。
更多的关于探索式测试的内容欢迎参考Thoughtworks同事刘冉的文章《探索式测试落地实践》和史湘阳的文章《敏捷项目中的探索性测试》。
4. 自动化测试分层策略
前面介绍端到端测试的时候提到了不同覆盖范围的测试,可能有单元测试和接口测试等。自动化分层策略就是针对这些不同粒度的测试类型进行分层,根据成本、稳定性等因素建议自动化测试需要考虑不同层的覆盖比例。
根据下图谷歌测试定律,我们能够很清晰的看到不同层的测试发现问题之后的修复成本的差异性,单元测试比端到端测试发现的问题修复成本要低得多,因此,通常建议测试分层应该倾向于测试金字塔的模式,也就是下图右侧的样子。Thoughtworks同事Ham Vocke的文章《测试金字塔实战》对此有很详细的介绍。
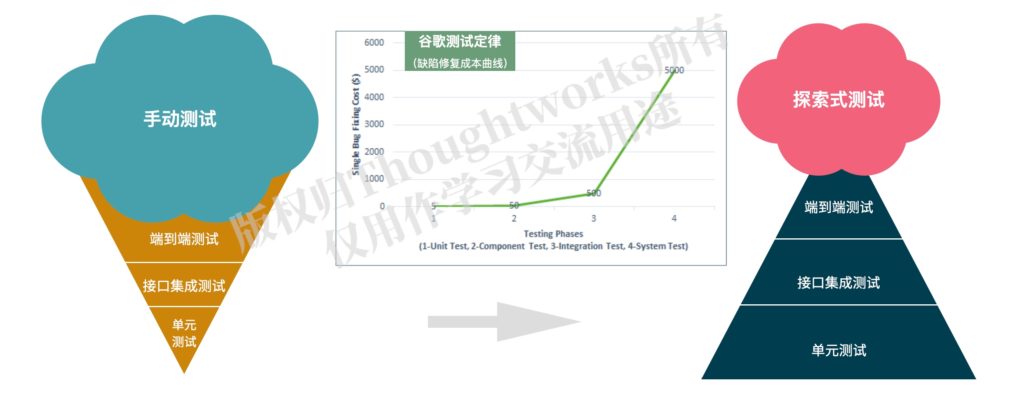
需要注意的是测试金字塔不是银弹,测试策略不是一成不变的,需要根据实际情况阶段性调整、演进,满足当下产品/项目质量目标才是关键。
更多的关于自动化测试分层的内容,还可以参考下列文章:
5. 测试用例
设计测试用例是每一名测试人员必备的基本功,测试用例的好坏直接影响到测试的有效性,测试用例的重要性不言而喻,但是要设计好的测试用例也不是一件很简单的事情。这里说的测试用例不区分手动用例和自动化用例。
好的测试用例
首先,我们有必要了解什么样的测试用例算是好的用例。
好的测试用例应该是正好能够覆盖所测软件系统、能够测出所有问题的。因此,好的测试用例需要具备下列特点:
- 整体完备性,且不过度设计:有效测试用例组成的集合,能够完全覆盖测试需求;同时也不会有用例超出测试需求。
- 等价类划分的准确性:每个等价类都能保证只要其中一个输入测试通过,其他输入也一定测试通过。
- 等价类集合的完备性:所有可能的边界值和边界条件都已经正确识别。
当然,因为软件系统的复杂性,不是所有测试用例都能做到正好100%覆盖,只能是做到尽量的完备。
测试用例设计方法
力求完备的测试用例,就需要了解相应的测试用例设计方法。测试用例应该是结合业务需求和系统特点,综合起来考虑设计。通常建议的用例设计方法有如下几种:
- 数据流法:基于业务流程中的数据流来切分测试场景的方法。考虑业务流程中的数据流,在数据存储或者发生变化的点进行流程的切断,形成多个用例场景。这个在我的文章《说起BDD,你会想到什么》里有介绍。
- 等价类划分法:把程序所有可能的输入数据划分为若干部分,然后从每个部分中选取少数有代表性的数据作为测试用例。等价类分有效等价类和无效等价类,根据等价类划分方法设计测试用例要注意无冗余和完备性。
- 边界值法:边界值分析方法是对等价类划分的补充,通常取正好等于、刚刚大于或刚刚小于边界的值作为测试数据,包括对输入输出的边界值进行测试和来自等价类边界的用例。
- 探索式测试模型法:推荐史亮和高翔两位老师的著作《探索式测试实践之路》,书中将探索式测试按测试对象不同分为系统交互测试、交互特性测试和单个特性测试三个层次,每个层次都分别介绍了不同的探索模型。虽然我不认为探索式测试需要严格按照这些模型来做,但是这些模型是可以帮助测试人员在探索过程中进行思考的,同时也是设计测试用例非常有价值的参考。

关于用例设计,还可以参考下列文章:
03 测试基本职责之三:实现和执行测试
第三个测试基本职责是实现和执行测试。
实现和执行测试就是以测试策略为指导、根据设计的测试来落地执行的相应的测试活动。这部分内容相对比较简单,从手动测试和自动化测试两个维度来简单介绍。
1. 手动测试
手动测试,顾名思义就是手工执行的测试,根据是否有提前设计好的测试用例(脚本)可以分为脚本化测试和探索式测试。
脚本化测试的执行,在有成熟测试用例的前提下,相对比较简单。但是,有些测试可能准备工作较为复杂,比如要通过长链路来准备测试数据、或者让系统到达测试触发的状态等,还有可能要考虑不同的环境对应的配置调整,同时也会包括环境的准备和管理。这些都是测试人员要做好手工测试可能需要涉及的内容。
关于探索式测试,在《探索式测试实践之路》中有详细介绍基于测程的测试管理(Session Based Test Management,SBTM)方法来执行探索式测试:将测试章程分解成一系列测程,测试人员在测程中完成一个特定测试章程的设计、执行和记录。
同样,这个方法对探索式测试有一定的指导意义,但是不建议严格规定必须按照这个模式来执行,不然的话就破坏了探索式测试的本质,达不到相应的效果。

2. 自动化测试
前面部分介绍了自动化测试的分层策略,把自动化测试的实现和执行放到这里介绍。
工具选型
自动化测试的实现依赖于自动化测试工具,对于工具的选型非常关键。通常在工具选型时需要考虑如下几个因素:
- 满足需求:不同的项目有不同的需求,根据需求来选择,不求最好,只求适合就好。
- 易于使用:常见的易用性,以及跟写测试的人技能匹配的易用性,都是需要考虑的。同时需要易于上手,如果一款工具对于新人不友好、很难上手的话,就很难动员大家都来积极地使用。
- 支持的语言:较好的作法是使用与项目开发相同的语言编写自动化脚本,让开发人员能够灵活地添加测试。
- 兼容性:包括浏览器、平台和操作系统之间的兼容。
- 报告机制:自动化测试的结果报告至关重要,优先选择能够提高完备的报告机制的工具。
- 测试脚本易于维护:测试代码跟产品代码一样重要,对测试的维护不可忽视,需要一款易于维护的工具。
- 工具的稳定性:不稳定性会导致测试有效性降低,首先要保证工具本身的稳定性,不然得不偿失。
- 代码执行速度:测试代码的执行速度直接影响到测试效率,比如Selenium和Cypress编写的测试代码执行速度就有很大差别。
测试实现
关于自动化测试的文章随处可见,这里强调一点,不要把测试数据写死在测试脚本里,要将数据独立出来,做到数据驱动,以提高测试代码的可复用性。
自动化测试的执行
是不是觉得自动化测试实现以后,执行就是简单的跑起来就可以呢?也不是。测试的执行也需要一定的策略,例如:对不同的测试按需设置不同的执行频率,将自动化测试跟流水线集成做到持续地测试,以持续反馈,最大化发挥自动化测试的价值。
关于自动化测试,推荐阅读以下文章:
04 测试基本职责之四:缺陷管理与分析
第四个测试基本职责是缺陷管理与分析。
缺陷对软件质量、软件测试来讲是非常宝贵的,好的缺陷管理和分析将会带来很大的价值,但是往往容易被忽略。
缺陷管理很重要的一个部分是搞清楚缺陷的生命周期是什么样的。往往大家觉得缺陷从发现到修复并验证通过了就可以了,其实并不止这些。我认为缺陷的生命周期应该包括如下阶段:
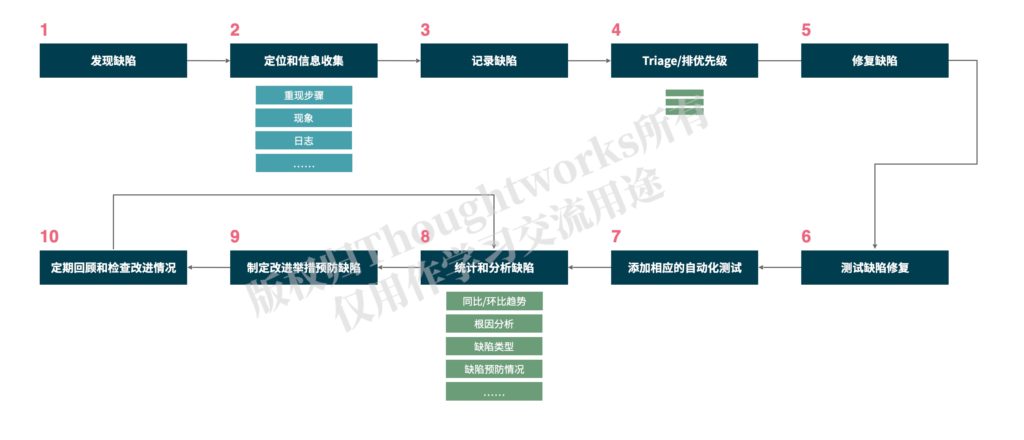
- 发现缺陷:这个比较简单,就是发现跟期望行为不一致的系统行为,或者性能、安全等非功能性问题。缺陷可能是在测试过程中发现,也可能由用户报告,还可以是例行日志分析或日志监控报警等等通过日志来发现。
- 定位和信息收集:发现缺陷之后,需要收集相应的缺陷信息并做初步定位。其中,缺陷相关信息要尽可能收集全,包括完整的重现步骤、影响范围、用户、平台、数据、屏幕截图、日志信息等。这一步有的时候可能需要开发或者运维人员帮忙。
- 记录缺陷:就是将收集到的日志信息记录在日志管理系统,关联相应的功能模块,并定义严重性。
- Triage/排优先级:对于记录的缺陷也不是所有的都要修复,所以要先对缺陷进行分类整理,确定缺陷是否有效、对有效缺陷的优先级排序,并且确定哪些是要修复以及在什么时间修复。这一步可能需要跟业务和开发人员一起来完成。
- 修复缺陷:这一步就交给开发人员来完成,对缺陷进行修复。
- 测试缺陷修复:对开发修复的缺陷进行验证,确保缺陷本身已经修复,并且需要对相关功能进行适当的回归测试。
- 添加相应的自动化测试:对于已经发现的缺陷,最好添加自动化测试,下次如果再发生类似的问题可以通过自动化测试及时地发现。自动化测试可以是单元测试、接口测试或者UI测试,根据实际情况结合自动化测试分层策略来定。这一步可能跟上一步顺序倒过来。
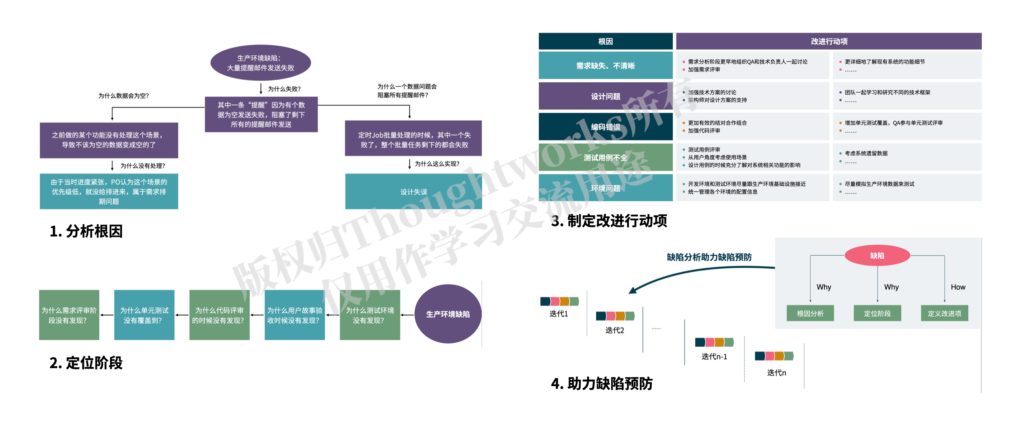
- 统计和分析缺陷:对缺陷的数量和严重程度进行统计分析其同比/环比趋势,用鱼骨图和5 Why法等分析缺陷发生的根因,定位缺陷引入的阶段,并且分析之前缺陷预防举措的执行效果等。
- 制定改进举措预防缺陷:根据第8步分析的结果,制定相应的可以落地的改进举措,以预防缺陷的发生。
- 定期回顾和检查改进情况:结合缺陷的统计分析,定期回顾缺陷管理的系列活动,并检查改进举措的执行情况,以持续优化缺陷管理流程,更好的预防缺陷。
关于缺陷的管理和分析,我之前有写过相应的文章,朋友们欢迎移步阅读:
05 测试基本职责之五:质量反馈与风险识别
第五个测试基本职责是质量反馈与风险识别。
测试对产品质量状态需要有清晰的认识,能够及时识别质量风险,并反馈给整个团队。
前面讲到缺陷的统计分析,与质量相关的除了有缺陷信息以外,可能还有很多其他的数据,将这些数据进行收集和统计,并且可视化展示给团队,将会帮助团队不同角色更好地做到为质量负责。在对质量数据的统计和分析过程中可以识别到相关的质量风险,将风险也一并反馈给团队很有必要。
质量状态信息可能包括测试覆盖率、缺陷相关数据、代码冻结期长度、测试等待时间等内容,具体需要收集哪些信息还得根据项目实际的质量需求来定制化。
质量反馈建议周期性的进行,由测试人员主导定义需要收集的数据有哪些,开发人员协同测试人员一起收集相关数据,后面的分析过程可能也需要开发人员的参与。
06 写在最后
本文为构建测试的体系化思维的基础篇,主要是从测试的基本职责出发展开,介绍了相关的方法、工具和实践,适合初级测试人员;当然,对于中高级测试人员,也可以对照着看看是不是这些基本职责平常都做到了,在自身的测试体系里边是否涵盖了相关内容。
【英文版 English Version】
00 Introduction
0.1 Three levels of Systematic Thinking for Testing
Do testing personnel lack systematic thinking?
How to build a quality assurance system for new product teams or projects?
Many of us have come across countless articles or training courses on testing and quality, which are not lacking in testing practices or technical content, but it is difficult to build our own testing system. Based on similar doubts from many friends and my own team practice and consulting experience over the years, I will discuss the construction of systematic thinking for testing at three different levels: basic, intermediate, and advanced.
- "Systems Thinking for Testing (Basics)"
- "Building Systematic Thinking for Testing (Intermediate)"
- "Building Systematic Thinking for Testing (Advanced)"
0.2 Overview of the Basics
I previously wrote an article "Great QA" targeting graduates who want to pursue a career in QA. The article discusses five basic responsibilities of QA:
- Understanding and clarifying business requirements
- Formulating strategies and designing tests
- Implementing and executing tests
- Defect management and analysis
- Quality feedback and risk identification
Recently, a friend asked me to share what aspects of systematic testing they should pay attention to. I thought of these five basic responsibilities again. In the original article, the five responsibilities were explained based on the demand for producing cups. This article will expand on each responsibility and analyze what testers need to do and how to do it from the perspective of testing practice and methodology.
01 First Basic Responsibility: Understanding and Clarifying Business Requirements
Business requirements are the source of software development, and correctly understanding requirements is crucial. Understanding and clarifying requirements is also an essential part of testing work.
1.1 Dimensions of Understanding and Clarifying Business Requirements
How can testers understand and clarify requirements? I believe testers can understand and clarify business requirements from the following three dimensions:
- End user
- Business process
- Business impact
Detailed content about these dimensions is introduced in the article "How Agile Testing Optimizes Business Value".
1.2 Testability of Requirements
In addition to understanding business requirements, the quality of requirement description also needs to be taken into account. Testability of requirements is the most important aspect of requirement quality, for the following reasons:
- If requirements are not testable, they cannot be accepted, and it is impossible to know whether the project has been completed successfully.
- Writing requirements in a testable manner can ensure that the requirements are correctly implemented and verified.
The testability of requirements is mainly reflected in the following three dimensions:
1. Completeness
The completeness of requirements mainly refers to the need to consider all process paths, require complete logical links, and include both positive and negative scenarios.
For example:
Clear definitions are needed for both successful login using correct username and password and what happens when incorrect username or password is used.
2. Objectivity
Requirement descriptions should not use subjective language, but should be supported with objective data and examples.
For example, the following subjective description is a very poor requirement example:
The system should be easy for experienced engineers to use and should minimize user errors as much as possible.
It is recommended to use the method of "Specification by Example" to write requirement documents, which expresses business rules through examples. This method is not only easy for different roles in the team to understand, but also avoids ambiguity.
3. Independence
Independence mainly refers to individual business functional points (user stories in agile development), which should be as independent as possible, with clear boundaries from other functions, to reduce the untestability caused by dependencies.
For example:
Inputs and outputs should be verifiable in the same functional point, and the input of Function A cannot be verified through the output of Function B.
In agile development, user stories follow the INVEST principle, which separates testability and independence. However, I believe that independence also affects testability and should be considered as a factor in testability.
02 Second Basic Responsibility: Developing Strategies and Designing Tests
Developing strategies and designing tests is the most critical responsibility among the five responsibilities, covering a wide range of content. It may seem like there are two parts, strategy and test design, but in fact, it includes every aspect that needs to be considered for testing. Below are some valuable aspects that I have selected to introduce separately.
2.1 One-page Test Strategy
Strategy is direction, and to do a good job in software testing, guidance from a testing strategy is essential. Testing strategies may be challenging for testers with little experience. However, the "One-page Test Strategy" that I proposed can help testers think and develop testing strategies suitable for their projects. The "One-page Test Strategy" is shown below:
The "One-page Test Strategy" clearly defines the three parts that need to be considered in a testing strategy:
- Guiding Principles: The team is responsible for quality.
- What to Test: The content to be tested.
- How to Test: Shift Left testing, Shift Right testing, and Lean testing.
For more details, please refer to my article on the "One-page Test Strategy".
2.2 Testing Process and Quality Gate
We often find that some teams have clearly defined testing process, but there are no strict criteria for what each step should achieve, and many quality-related tasks are not done well, resulting in huge pressure on testers in the later stages of testing or low final quality of delivery.
The "One Page Test Strategy" already includes the testing process part, but it is mentioned again here mainly to emphasize the importance of quality gates. The testing process may be different for each project or team, but regardless of the steps included in the testing process, the output of each step must be clearly defined, that is, the quality gates of each step must be defined clearly, as shown in the following figure:
Note: This figure is for illustration purposes only. The actual situation needs to be adapted according to the team's own situation.
2.3 Typical types of testing
The testing process figure example above lists various types of testing, but there are actually many more types of testing than those shown. Due to length limitations and the fact that this is not the focus of this article, here only introduces four typical types of testing that are closely related to testers. These four types of testing are classified differently, and a detailed explanation is not sought here. For those who are interested but unclear, please search online for more information.
1. Smoke testing
Smoke testing originated from the testing of circuit boards, which involved powering on the board to see if it emitted smoke. If smoke was produced, it meant that the board could not function properly and there was no need to validate other functions.
In software, smoke testing verifies the basic behavior of the software, such as "Does the program run?", "Does the user interface open?" or "Is the click event effective?" Only when the smoke test passes is it necessary to carry out further validation of the software's functional testing; otherwise, a new version must be repaired before continuing.
We found that some teams only perform smoke testing on new developed features, which is not quite correct, or rather, this test is not called smoke testing. Smoke testing should verify the basic behavior of the entire system, regardless of whether the feature is old or new.
2. Regression testing
The purpose of regression testing is to verify whether the development of new features or bug fixes have affected existing features. Therefore, regression testing mainly focuses on existing features, and testing new features is not called regression testing.
There are usually four strategies for regression testing:
- Full regression: This means testing all existing features, regardless of their importance. This strategy is costly, but it provides comprehensive coverage, and is often used for financial products with high quality requirements.
- Selective regression: This involves communication between testing and development teams to understand the areas of code that could potentially impact existing functionality, and selecting those affected feature modules for regression testing. This approach may miss some unanticipated but related features, but is a more economical approach.
- Index-based regression: This approach usually requires the team to have a coverage requirement for regression testing, such as a mandate to cover 50% of existing feature test cases, and not to fall below this coverage rate. This method solely relying on coverage numbers is the least recommended, as even though coverage targets are met, some features may have been missed.
- Accurate regression: Accurate regression is a very popular accurate testing method that uses technical means to associate the scope of code changes with test cases and executes affected cases precisely. This method provides the most reliable quality, but the cost of implementing accurate testing is very high.
Regression testing can be done manually or through automation, but the amount of regression testing required is usually large, so automated testing is more efficient.
3. End-to-End Testing
End-to-end testing is classified based on the granularity of test coverage, and is related to unit testing and interface testing.
End-to-end testing verifies the entire software and its integration with external interfaces from start to finish. Its purpose is to test the dependencies and data integrity of the entire software, as well as its communication with other systems, interfaces, and databases, in order to simulate complete business processes. Therefore, end-to-end testing is the most valuable type of testing as it reflects users' real business behavior.
However, because end-to-end testing involves various related components of the system and external dependencies, its stability and execution costs are relatively high. Therefore, there are interface testing and unit testing with smaller coverage ranges. These tests are usually implemented by isolating dependencies and will not be discussed in detail here.
4. Exploratory Testing
Exploratory testing was proposed by Dr. Cem Kaner in 1983 and is in contrast to scripted testing.
Dr. Cem Kaner defined exploratory testing as follows:
"Exploratory testing is a style of software testing that emphasizes the personal freedom and responsibility of the individual tester to continually optimize the quality of his/her work by treating test-related learning, test design, test execution, and test result interpretation as mutually supportive activities that run in parallel throughout the project."
The core of exploratory testing is to iterate quickly by treating test-related learning, test design, test execution, and test result interpretation as a cycle in order to continuously collect feedback, adjust testing, and optimize value.
Exploratory testing particularly requires testers to have subjective initiative and to work in an environment that encourages test innovation. If the requirements for testing metrics are too high and the testers' subjective initiative cannot be fully utilized, the effectiveness of exploratory testing is limited.
Exploratory testing is a relatively free testing style that should not be restricted by various testing models, and its execution method should not be strictly defined, as this would affect its effectiveness.
For more information on exploratory testing, please refer to the article "Exploratory Testing Practice" by my colleague Liu Ran at Thoughtworks and the article "Exploratory Testing in Agile Projects" by Shi Xiangyang.
2.4 Automated Testing Layered Strategy
When introducing end-to-end testing earlier, different coverage ranges of tests were mentioned, including unit testing and interface testing. The layered strategy for automated testing is to stratify these different granularities of test types and suggest that automated testing should consider the coverage ratio of different layers based on factors such as cost and stability.
According to Google's testing law shown in the figure below, we can clearly see the differences in the repair costs after different layers of tests discover problems. The repair cost of problems found by unit testing is much lower than that of end-to-end testing. Therefore, it is generally recommended that testing stratification should tend to the pattern of the Testing Pyramid, as shown on the right side of the figure below. Ham Vocke, a colleague at Thoughtworks, provides a detailed introduction to this in his article "The Practical Test Pyramid".
It is worth noting that the Testing Pyramid is not a silver bullet and the testing strategy is not fixed. It needs to be adjusted and evolved periodically according to the actual situation to meet the current product/project quality objectives.
For more information about automated testing layering, you can also refer to the following articles:
- "Lean Testing"
- "Thinking and Practice of Microservices Testing"
- "Testing Pyramid Is Not a Silver Bullet"
- "Seven-Year Itch of Automated Testing for Legacy Systems"
2.5 Test Cases
Designing test cases is a basic skill that every tester must have. The quality of test cases directly affects the effectiveness of testing, and the importance of test cases is self-evident. However, designing good test cases is not a simple task. Here, test cases are not distinguished between manual cases and automated cases.
1. Good Test Cases
First of all, it is necessary to understand what kind of test cases are considered good.
Good test cases should be able to completely cover the tested software system and be able to detect all issues. Therefore, good test cases should have the following characteristics:
- Overall completeness without excessive design: A set of effective test cases that can completely cover the testing requirements without exceeding them.
- Accuracy of equivalence partitioning: Each equivalence class can guarantee that if one of the inputs passes the test, the other inputs will also pass the test.
- Completeness of equivalence class collection: All possible boundary values and boundary conditions have been correctly identified.
Of course, due to the complexity of the software system, not all test cases can achieve 100% coverage, but can only achieve as much completeness as possible.
2. Test Case Design Method
To strive for complete test cases, it is necessary to understand the corresponding test case design methods. Test cases should be designed by considering both business requirements and system characteristics. The following test case design methods are commonly recommended:
- Data flow method: A method of dividing test scenarios based on data flow in the business process. Consider the data flow in the business process, cut off the process at the point where data is stored or changes, and form multiple scenario cases. This is described in my article "What Do You Think of When We Talk About BDD?".
- Equivalence partitioning method: Divide all possible input data of the program into several parts and select a few representative data from each part as test cases. Equivalence classes are divided into valid and invalid equivalence classes, and designing test cases based on equivalence partitioning method requires attention to non-redundancy and completeness.
- Boundary value method: The boundary value analysis method is a supplement to the equivalence partitioning method. Typically, test data that is just equal to, just greater than, or just less than the boundary is taken, including testing input-output boundary values and cases from equivalence class boundaries.
- Exploratory testing model: Recommended books by SHI Liang and Gao Xiang, "The Road to Exploratory Testing Practice", classify exploratory testing into system interaction testing, interaction feature testing, and single feature testing at different levels, and introduce different exploratory models for each level. Although I do not believe that exploratory testing needs to strictly follow these models, they can help testers think during the exploration process and are also valuable references for designing test cases.
For test case design, the following articles can also be referenced:
- "Business Requirements and System Functions"
- "Does Agile QA Need Test Cases?"
- "Test Case Analysis, Design, and Management"
03 Third Basic Responsibility: Implementation and Execution of Tests
The third basic responsibility of testing is the implementation and execution of tests.
Implementation and execution of tests means carrying out the corresponding test activities based on the testing strategy and the designed tests. This part is relatively simple and can be briefly introduced from two dimensions: manual testing and automated testing.
3.1 Manual Testing
Manual testing, as the name suggests, is testing that is done manually. Depending on whether there are pre-designed test cases (scripts), it can be divided into scripted testing and exploratory testing.
The execution of scripted testing is relatively simple with mature test cases. However, some tests may require complex preparation work, such as preparing test data through a long chain, or making the system reach the state of triggering the test. In addition, it may be necessary to consider the configuration adjustments corresponding to different environments, as well as the preparation and management of the environment. These are the contents that the tester may need to be involved in for manual testing.
Regarding exploratory testing, the book "Exploratory Testing: A Practical Guide" introduces the Session-Based Test Management (SBTM) method based on test levels to carry out exploratory testing. Testers decompose the testing charter into a series of test levels, and complete the design, execution, and recording of a specific testing charter in the test level.
Similarly, this method has certain guiding significance for exploratory testing, but it is not recommended to strictly follow this mode of execution, otherwise it will destroy the essence of exploratory testing and not achieve the corresponding effect.
3.2 Automated Testing
The previous section introduced the layering strategy of automated testing, and here we will focus on the implementation and execution of automated testing.
1. Tool Selection
The implementation of automated testing relies on automated testing tools, so the selection of tools is critical. Generally, the following factors need to be considered when selecting tools:
- Meeting requirements: Different projects have different requirements, and the selection should be based on the requirements. We should aim for suitability rather than the best tool.
- Easy to use: Usability is important, as well as matching the skills of the testers. It is also important that the tool is easy to get started with. If a tool is not user-friendly and difficult to get started with, it will be hard to motivate everyone to use it actively.
- Language support: The best practice is to use the same language as the project development to write automation scripts, which enables developers to flexibly add tests.
- Compatibility: Including compatibility between browsers, platforms, and operating systems.
- Reporting mechanism: The result report of automated testing is crucial, so it is preferred to select a tool with a comprehensive reporting mechanism.
- Easy maintenance of test scripts: Test code is as important as product code, and the maintenance of tests cannot be neglected. We need a tool that is easy to maintain.
- Tool stability: Instability can reduce the effectiveness of testing, so the stability of the tool itself should be ensured, otherwise, the gains may not outweigh the losses.
- Code execution speed: The execution speed of test code directly affects the efficiency of testing. For example, there is a big difference in the execution speed of test code written with Selenium and Cypress.
2. Test Implementation
Articles on automated testing can be found everywhere. Here, we emphasize not to hard code test data in the test scripts. Data should be independent and driven to improve the reusability of the test code.
3. Execution of Automated Testing
Do you think that after implementing automated testing, the execution is as simple as running the tests? Not really. The execution of testing also requires certain strategies, such as setting different execution frequencies for different tests, integrating automated testing with pipelines to achieve continuous testing and feedback, and maximizing the value of automated testing.
Regarding automated testing, we recommend reading the following articles:
- "New BDD Tool Gauge and Taiko"
- Thoughtworks Insights (in Chinese) on Automated Testing
- Automation Testing Articles on Liu Ran's Website
04 Fourth Basic Responsibility: Defect Management and Analysis
The fourth basic responsibility of testing is defect management and analysis.
Defects are very valuable for software quality and software testing, and good defect management and analysis can bring great value, but it is often overlooked.
A crucial part of defect management is understanding the defect's life cycle. People often think that defects only need to be discovered, fixed, and verified, but there are more steps to the life cycle than these. I believe that the defect life cycle should include the following stages:
- Defect discovery: This is relatively simple, it means discovering system behavior that is inconsistent with expected behavior, or non-functional problems such as performance and security issues. Defects may be discovered during testing, reported by users, or discovered through routine log analysis or log monitoring alerts.
- Information collection and defect diagnosis: After a defect is discovered, relevant defect information needs to be collected and preliminary diagnosis performed. The relevant defect information should be collected as completely as possible, including complete reproduction steps, scope of impact, users, platforms, data, screenshots, log information, etc. Sometimes, development or operations personnel may need to help with this step.
- Defect recording: The collected log information is recorded in the log management system, associated with the corresponding functional module, and severity is defined.
- Triage/prioritization: Not all recorded defects need to be fixed, so defects need to be classified and sorted by priority to determine whether they are valid, which are to be fixed, and when to fix them. This step may need to be done with business and developer.
- Defect fixing: This step is completed by the developer, fixing the defect.
- Defect verification: Verify that the defect has been fixed by the developer and perform appropriate regression testing of the related functionality.
- Add corresponding automated testing: For defects that have already been discovered, it is best to add automated testing to detect similar problems in a timely manner. Automated testing can be unit testing, interface testing, or UI testing, depending on the actual situation and the layered automation testing strategy. This step may be reversed in order with the previous step.
- Defect statistics and analysis: Statistical analysis of the number and severity of defects, their year-on-year or month-on-month trends, analysis of the root causes of defects using fishbone diagrams and 5-Why method, identification of the stage where defects are introduced, and analysis of the effectiveness of previous defect prevention measures.
- Develop improvement measures to prevent defects: Based on the results of step 8, develop corresponding, feasible improvement measures to prevent defects from occurring.
- Regularly review and check the improvement status: Based on the statistical analysis of defects, regularly review the series of activities in defect management, check the implementation of improvement measures, continuously optimize the defect management process, and better prevent defects.
Regarding defect management and analysis, I have previously written relevant articles. Friends are welcome to read them:
- "Effective Management of Software Defects"
- "How Defect Analysis Helps Build Quality In"
- "All the trouble caused by dirty data"
05 Fifth Basic Responsibility: Quality Feedback and Risk Identification
The fifth basic responsibility of testing is quality feedback and risk identification.
Testing needs to have a clear understanding of the product's quality status, be able to identify quality risks in a timely manner, and provide feedback to the entire team.
In addition to defect information, there may be many other quality-related data, which can be collected and statistically analyzed. Visualizing this data and presenting it to the team will help team members in different roles better take responsibility for quality. It is also necessary to identify quality risks during the statistical analysis of quality data and provide feedback to the team.
Quality status information may include test coverage, defect-related data, code freeze period length, test waiting time, and other content. Specific information that needs to be collected should be customized according to the actual quality requirements of the project.
It is recommended to conduct periodic quality feedback. tester should lead the definition of the data that needs to be collected, and developer should work with tester to collect relevant data. developer may also need to participate in the subsequent analysis process.
06 Conclusion
This article is the foundation of building a systematic thinking for testing. It mainly starts from the basic responsibilities of testing, introduces related methods, tools, and practices, and is suitable for junior tester. Of course, for intermediate and senior tester, they can also check whether they have fulfilled these basic responsibilities in their own testing system.
Finally, you can follow my self-published book "Beyond Testing (in Chinese)", which introduces content that tester or QA need to pay attention to beyond the basic responsibilities of testing.
通告:测试类型 - 与ChatGPT pair完成的测试类型清单 - BY林子
通告:QA的关注点 - 一颗石榴给QA带来的启示 - BY林子
通告:组织级测试体系 - 构建测试的体系化思维(高级篇) - BY林子
通告:文章是“自己的”好 - BY林子
通告:构建测试的体系化思维(进阶篇) - BY林子 - 质量 - 质量内建
通告:Navid的质量框架 Navid's Quality Pillars - BY林子 团队质量改进助手